Lokálne AI modely alebo Ako sme postavili vlastný AI chat server: Open WebUI + Ollama - časť 1
Posted on 13 May 2025 by Janci — 12 min

Úvod
Naším cieľom bolo vytvoriť bezpečné, lokálne a dostupné AI riešenie pre vývojárov a interný tím bez závislosti na externých cloud službách. Projekt je vytváraný v spolupráci s AI agentom. Texty sú generované pomocou AI agenta.
Pre potreby rýchlejšiej inštalácie a konfigurácie sú prvotné fázy projektu konfigurované bez využitie SSL komunikácie. SSL komunikácia bude dokonfigurovaná v ďalších fázach projektu.
Prečo ísť cestou lokálneho nasadenia
Rastúca potreba lokálnych AI riešení bez závislosti na cloude.
- Ochrana citlivých firemných údajov.
- Skútsenosti s nasadzovaním a správou vlastných LLM infraštruktúr.
- Príprava na budúce AI aplikácie a vlastné RAG systémy.
Základné vlastnosti
- Maximálna bezpečnosť dát - Citlivé informácie zostávajú výhradne vo vašom prostredí bez odosielania do cloudu
- Plná kontrola nad infraštruktúrou - Nezávislosť od externých služieb a možnosť prispôsobiť systém vlastným potrebám
- Žiadne paušálne poplatky - Jednorazová investícia do hardvéru namiesto neustálych platieb za API volania.
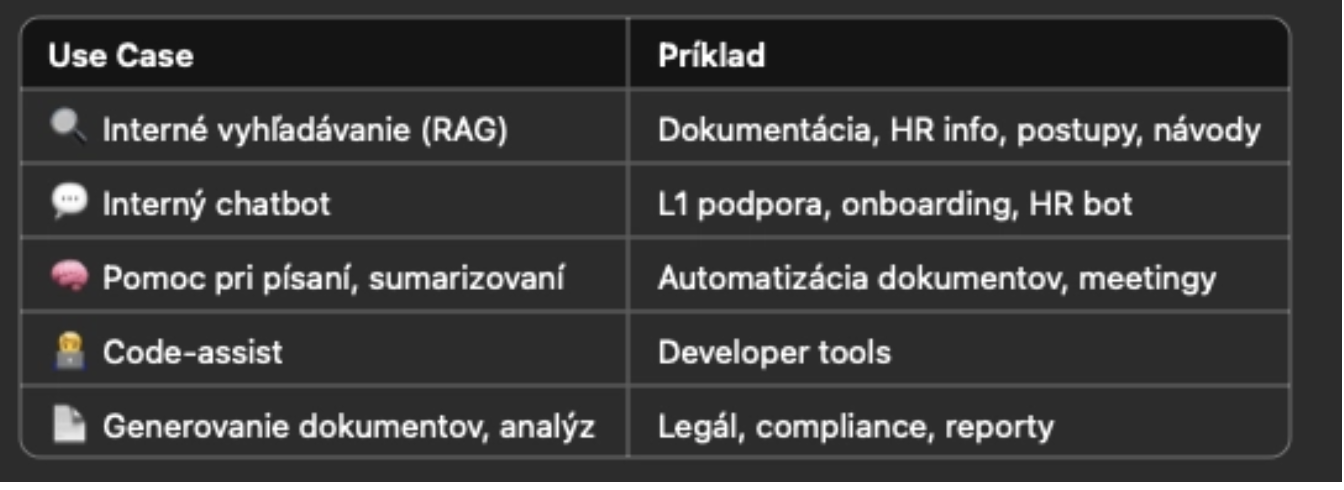
Príklady použitia v Cybersec
Výber modelu závisí od použitia - analýza kódu, dotazy, generovanie pravidiel, atď. Tu sú odporúčané modely pre lokálne nasadenie.
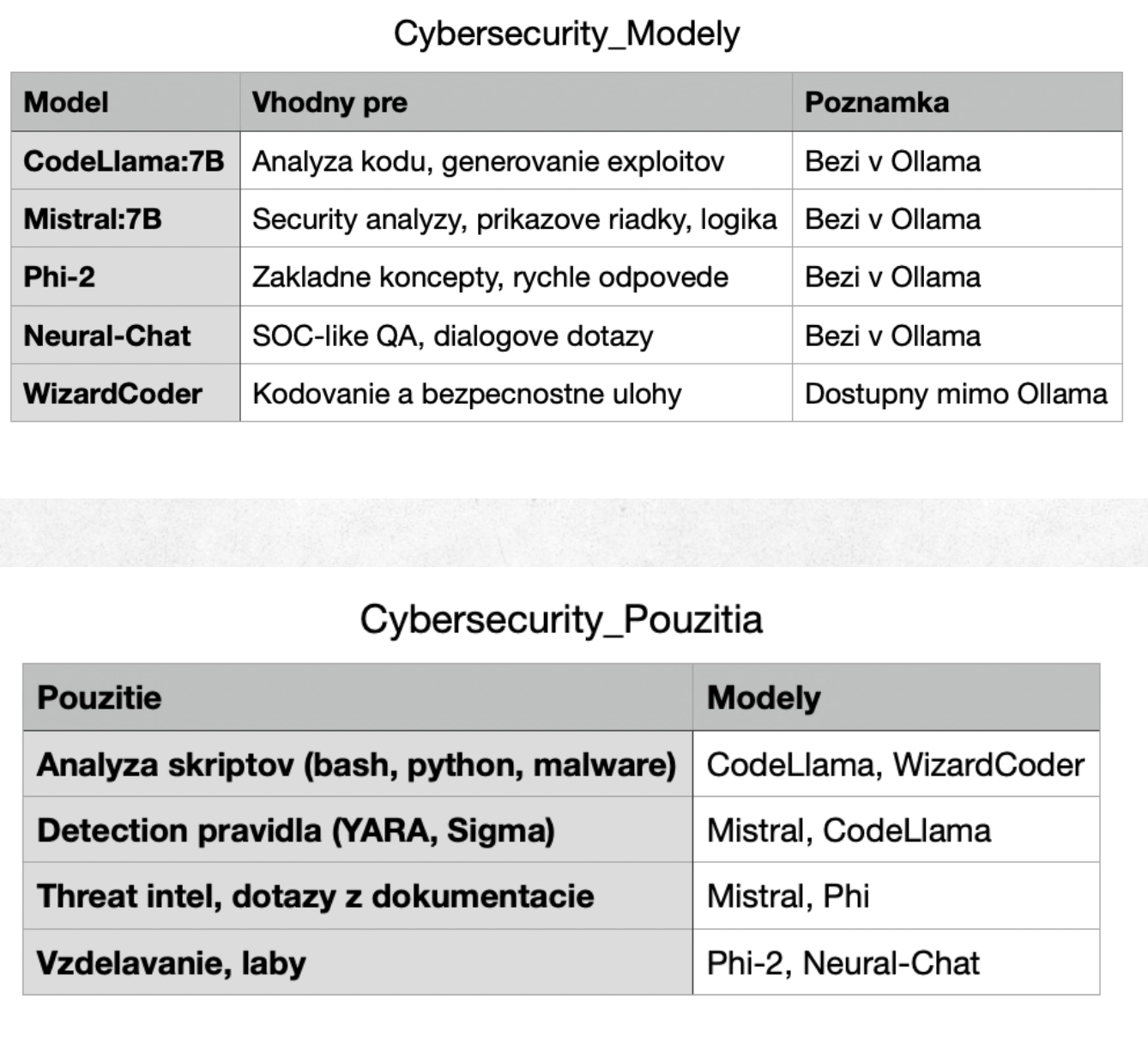
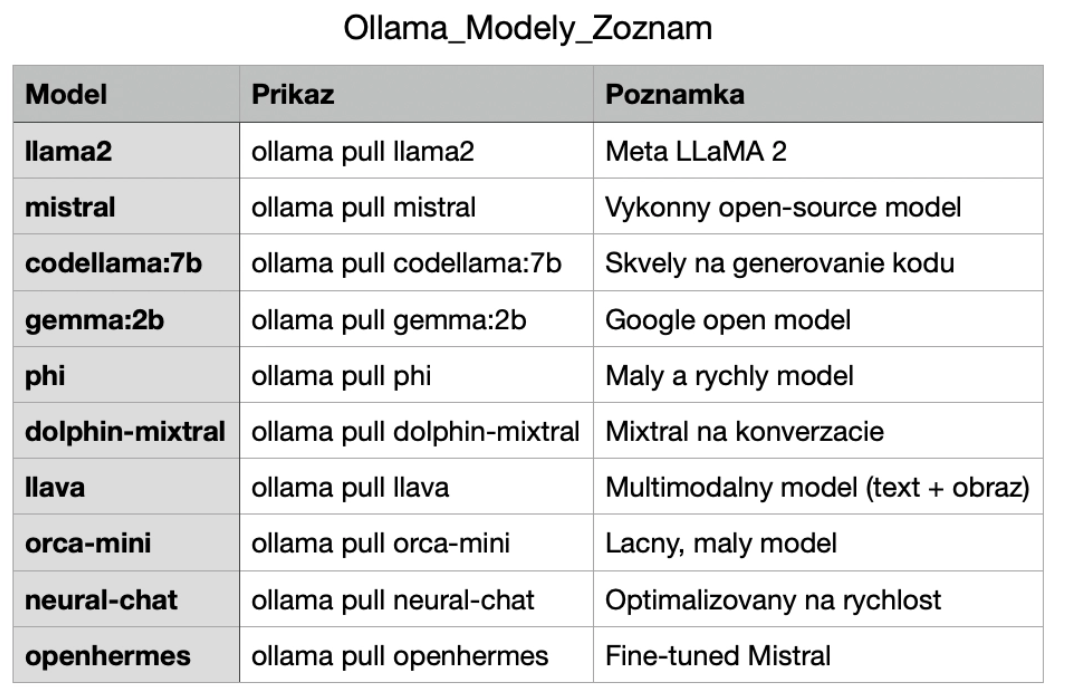
Porovnanie modelov pre náš projekt
V doleuvedenej tabuľke je prehľad modelov, ktoré je možné vzhľadom na náš HW použiť.

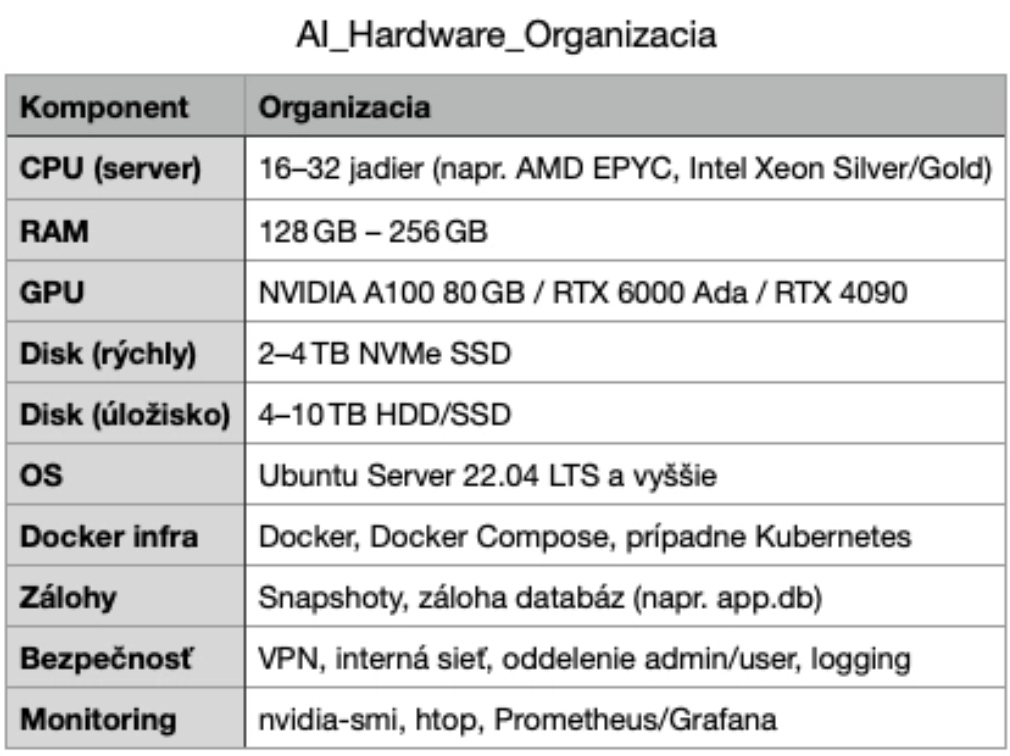
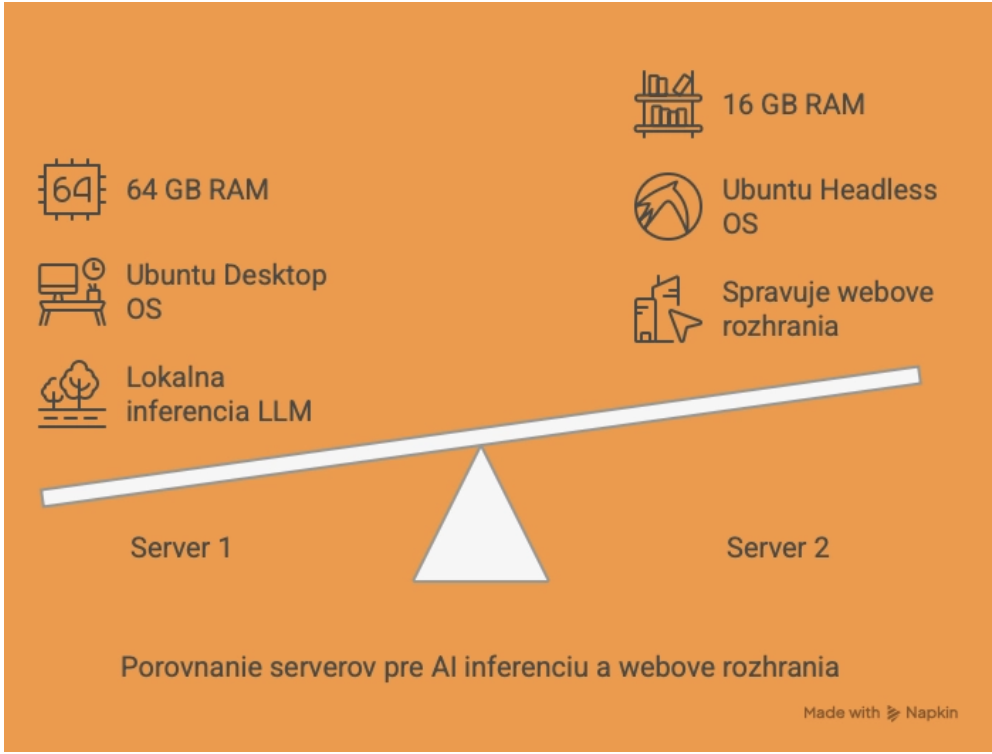
Hardvér
Návrh hardvéru pre lab

Návrh hardvéru pre organizáciu
Aktuálny Hardvér v Labe
Začíname s bežným HW. Žiadne drahé karty a server. Prečo? Jednak overiť použiteľnosť riešenia ale hlavne zistiť možnosti zabezpečenia modelu a použitia v internej infraštruktúre.

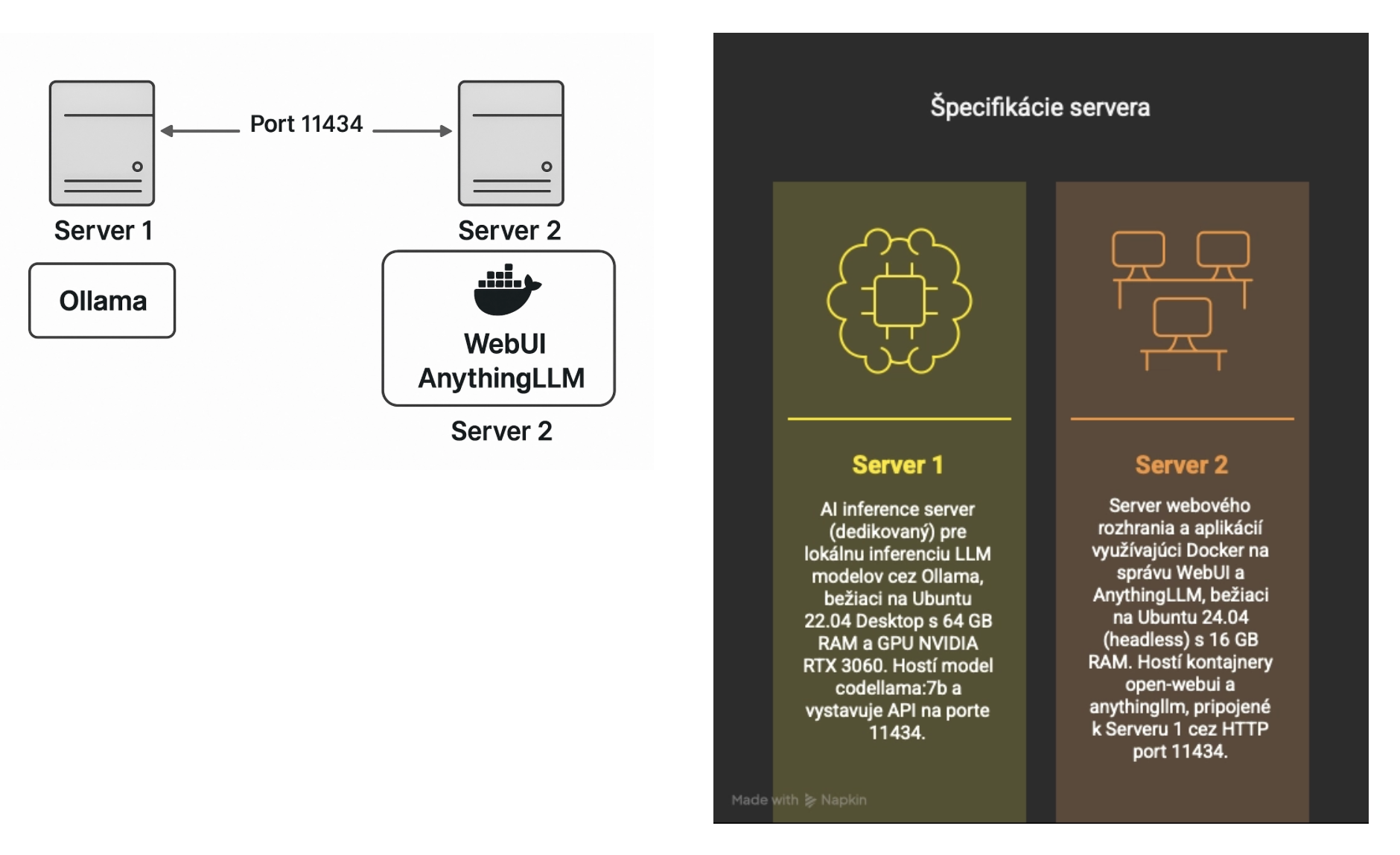
Použité softvérové komponenty
- Ollama - Lokálny LLM server na modely (codellama, gemma, atď.)
- Open WebUI - Jednoduché UI rozhranie pre prácu s modelmi
- AnythingLLM - Web UI na upload dokumentov a RAG (Retrieval Augmented Generation)
- Docker + Docker Compose - Správa všetkých služieb
Pre potreby nášho projektu sú použité tzv. kvantizované modely.
Co je kvantizovaný format?
Kvantizácia je proces zmenšenia čísel, s ktorými AI model pracuje. Z vysokopresných (napr. 32-bit float) na formáty nižšej presnosti (napr. 4-bit, 8-bit). Výhody kvantizácie sú:
- Nižšia spotreba pamäte (VRAM, RAM)
- Vyššia rýchlosť inferencie
- Schopnosť spustiť väčšie modely na menšom hardware
Modely sa kvantizujú do formátov ako Q4, Q5, Q8 kde číslo udáva počet bitov použitých na reprezentáciu váh modelu.
Ako rozpoznať kvantizovaný model?
- Podľa názvu modelu: obsahuje Q4, Q5, Q8 alebo slova ako int4, int8.
- Podľa formátov súborov: .gguf, .bin, .safetensors.
- Podľa veľkosti súboru: 7B model v FP16 má 13-15GB, kvantizovaný Q4 model má len 3-6GB.
- Podľa popisu na webe: zmienky o "quantization", "4-bit model", "GPTQ".
- Pri načítaní do inferenčného enginu: vypisuje sa info o použitom kvantizovanom formáte (napr. int4, Q4_K).
Ako pracujú tokeny v LLM modeloch
Čo je token? Token je úsek textu (slovo, časť slova, znak, interpunkcia), ktorý model spracováva. Tokenizácia rozdelí text na tokeny pred spracovaním modelom.
Použitie tokenov
Tokeny sa rátaju vo vstupe (prompt), výstupe (odpoveď) a v celkovom kontexte (vstup + výstup dohromady).
Praktické limity pre RTX 3060 12GB
- CodeLLaMA 7B: cca 4096 az 8192 tokenov
- Mistral 7B: cca 8192 tokenov
- Gemma 3 12B: cca 4000-6000 tokenov
- Gemma 2B: viac ako 16000 tokenov
Prečo na tom záleží
Čím viac tokenov, tým viac VRAM potrebujete. Ak prekročíte limit, model moze zabudnúť začiatok promptu. Cloud sluzby si účtujú podľa počtu tokenov.
Ako zistiť počet tokenov
Použiť online nástroje ako OpenAI Tokenizer alebo lokálne nástroje ako tiktoken, transformers, llama.cpp.
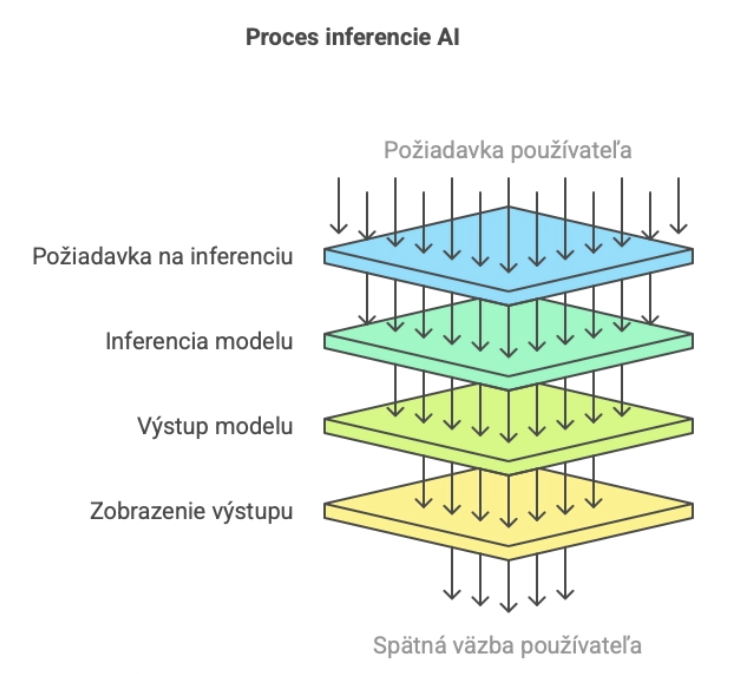
Čo je inferencia v AI
Inferencia je proces, keď AI model (napr. LLM ako Mistral alebo Codellama) odpovedá na tvoju otázku na základe naučených dát.
Jednoducho povedané:
- Tréning je, keď sa model učí.
- Inferencia je, keď model odpovedá.
Ako to funguje:
- Input (prompt): napr. otázka, príkaz
- Model: použije svoje váhy a parametre
- Output: textová odpoveď
Rozdiel medzi tréningom a inferenciou:
- Tréning: model sa učí zo stoviek GB dát, vykonáva sa raz.
- Inferencia: model používa naučené vedomosti na odpoveď - deje sa to pri každom dotaze.
Inštalácia serveru pre Ollama model
OS: Ubuntu 22.04 Inštalácia bola vykonaná na HW, tzn. nie je to virtualizovaný OS. V serveri je pripojená naša hlavná grafická karta NVIDIA RTX 3060.
Prečo starrší OS?
Z pohľadu bezpečnosti je samozrejme najlepšie používať najaktuálnejši OS. Tu sme všas pre rýchlosť vybudovania prostredia použili overené verzie. V budúcosti je dôležitá migrácia na novší OS.

Inštalácia Ollama na Server
Aktualizácia systému
sudo apt update && sudo apt upgrade -y
Inštalácia ovládačov NVIDIA
sudo apt install -y nvidia-driver-535
Reštart systému po nainštalovaní ovládača
sudo reboot
Inštalácia základných nástrojov
sudo apt install -y build-essential git curl python3-pip unzip
Inštalácia Ollama (LLM engine)
curl -fsSL https://ollama.com/install.sh | sh
Overenie inštalácie NVIDIA (nvidia-smi)
nvidia-smi
Príprava prostredia pre modely
mkdir -p ~/llm_models
Odporúčané Python balíčky
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip3 install langchain llama-index
sudo reboot
Spustenie modelu 7b
ollama run codellama:7b
Po spustení modelu máte možnosť pracovať/dotazovať sa priamo v terminály.
Zoznama možných modelov Ollama
Ako to teda funguje v praxi
- ollama run model je interaktívny režim — určený na jednu reláciu.
- Inference API (napr. https://localhost:11434/api/generate) automaticky spustí a načíta model, keď je potrebný.
- Ak je model nečinný, môže byť uvoľnený z RAM.
Ako spravovať modely v Ollama
Ollama podporuje viacerémodely naraz. Každý model môže byť volaný samostatne (napr. z OpenWebUI alebo API) a Ollama sa postará o paralelné obsluhovanie požiadaviek.
Ako sa modely správajú
- Modely sa načítavajú do pamäte pri prvom volaní
- Ak je málo pamäte, menej používané modely sa môžu vyhodiť a znova načítať neskôr
- Viacero používatelov môže naraz volať rôzne modely
Užitočné príkazy
- ollama list - Zoznam stiahnutých modelov
- ollama ps - Zobrazí, ktoré modely boli aktívne
- ollama stop
- Odstrání model z pamäte - ollama rm
- Trvalo odstrání model z disku
Tip pre optimalizaciu
Ak nepotrebujete konkrétny model, je možné ho stopnúť cez ollama stop, čím sa uvolní RAM/VRAM. Nie je to však nutné, ak server zvláda bez problémov viacerých používateľov naraz.
Pridanie webového rozhrania
Pre jednoduchšiu prácu s modelom sme nainštalovali a nakonfigurovali OpenWebUI.
Najdôležitejšia je ale možnosť riadenia prístupov, teda riešenie práce s AI modelmi s lepším prístupom a riadením bezpečnosti.
Čo je Open WebUI?
Open WebUI je jednoduché, ale výkonné webové rozhranie pre prácu s jazykovými modelmi (LLM), ktoré beží nad Ollama serverom.
Na čo ho používame?
- Chatovanie s modelmi ako codellama:7b, mistral, phi
- Správa používateľov (admin/user)
- Vebový prístup k modelom bez CLI
- Testovanie a ladenie AI promptov
Hlavné vlastnosti
- Napojenie na Ollama cez HTTP API
- Podpora viacerých modelov
- Admin email a práva
- Ukladanie konverzácií do databázy (napr. SQLite)
- Nasadenie cez Docker s minimálnou konfiguráciou
Prečo sme ho vybrali:
- Open source a aktívne vyvíjaný
- Jednoduché a moderné UI
- Výborná integrácia s Ollama
- Ľahké na úpravy a rozšírenia
Východisková konfigurácia
- Server2 s Ubuntu 24.04, Docker a Docker Compose
- Ollama model beží na druhom serveri - default port 11434
- Cieľ bol nakonfigurovať WebUI dostupné na https://server2:3000
Inštalácia Docker na Ubuntu 24.04
sudo apt-get remove docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc
sudo apt updatesudo apt install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo tee /etc/apt/keyrings/docker.asc > /dev/null
sudo chmod a+r /etc/apt/keyrings/docker.asc
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] \
https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin
docker-compose-plugin
docker compose version
Spustenie docker inštancie OpenAI WEBui
Pre inštaláciu a konfiguráciu docker inštancie sme použili docker-compose.yml z oficiálneho zdroja.
Inštalácia a konfigurácia AnythingLLM
Cieľ:
Vytvorit lokalne riesenie na spravu a vyuzitie AI modelov cez kombinaciu:
- Ollama (lokalny LLM server)
- AnythingLLM (webove rozhranie pre pracu s dokumentmi a AI)
Východisková konfigurácia
- Server2 s Ubuntu 24.04, Docker a Docker Compose
- Ollama model beží na druhom serveri - default port 11434
- Cieľ bol nakonfigurovať AnythingLLM dostupné na https://server2:3001
Čo je AnythingLLM
- Webová aplikácia na správu dokumentov a využitie AI cez Ollama
- Upload a indexovanie dokumentov
- Vyhľadávanie a QA nad vlastnými dátami
AnythingLLM je open-source riešenie, ktoré ti umožní nahrávať vlastné dokumenty a následne s nimi komunikovať cez veľké jazykové modely (LLM) — priamo lokálne, bez nutnosti cloudu.
Prečo AnythingLLM
- Vytvorenie RAG riešenia – model odpovedá na základe nahraných dokumentov.
- Nahrávanie PDF, DOCX, TXT, webových stránok…
- Indexácia a embedding textu – cez Ollama alebo OpenAI.
- Chatovanie s vlastnými dokumentmi – bez toho, aby opustili tvoj server.
- Funguje s Ollama modelmi ako mistral, codellama, phi, atď.
- Beží offline – ideálne pre bezpečnostné projekty.
- Nepotrebujeme cloudové API kľúče.
- Flexibilné napojenie na rôzne modely.
- Môžeme tvoriť vlastné "workspaces" pre rôzne oblasti, tímovú spoluprácu alebo zákazníkov.
Čo je RAG
RAG = Retrieval-Augmented Generation = "Generovanie doplnené vyhľadávaním" Jazykový model najprv vyhľadá relevantné informácie z tvojich dát (napr. PDF, databázy, weby) a až potom vytvorí odpoveď, ktorá tieto dáta zohľadňuje.
Výhody RAG
- Pracuje s tvojimi súkromnými dátami
- Znižuje halucinácie (vymýšľanie)
- Nemusíš model pretrénovať
- Ľahko aktualizovateľné dáta
Inštalácia a konfigurácia AnythingLLM - Docker inštancia
AnythingLLM sme nakonfigurovali a spustili ako docker inštanciu. Použili sme oficiálny docker-compose.yml zo stránky github.
Zmeny v konfigurácii:
Vytvoriť lokálny adresár pre centrálne úložisko pre dáta potrebné pre RAG.
mkdir -p /home/ubuntu/anythingllm_storage
Nastavenie práv pre daný adresár:
sudo chown 1000:1000 /home/ubuntu/anythingllm_storage
Nastaviť cestu k danému adresáru v docker-compose.yml
volumes:
anythingllm_storage:
driver: local
driver_opts:
type: none
o: bind
device: /home/ubuntu/anythingllm_storage
Zistenie: V docker inštancii nefunguje Live Document Sync. Inštalácia Desktop aplikácie AnythingLLM s prepojením na interný Ollama server je funkčná.
Problémy: Dokumenty sa ukladajú lokálne na pracovnú stanicu. Je potrebné následne vymyslieť napríklad zdieľanie s tímom atď.
Vyhodnotenie aktuálneho stavu
- Ollama (Server 1): Centrálna AI infraštruktúra, kde bežia modely (napr. codellama, phi, gemma).
- OpenWebUI (Server 2): Webové rozhranie s výberom modelov pre viacerých používateľov.
- AnythingLLM Desktop: Len lokálne (napr. Mac), bez možnosti centrálneho dokumentového úložiska.
Zmena grafickej karty
Pre ďalšie pokračovanie v projekte sme vymenili Nvidia RTX 3060 za Nvidia A4000
Porovnanie GPU: NVIDIA RTX 3060 vs NVIDIA RTX A4000
| Parameter | NVIDIA RTX 3060 | NVIDIA RTX A4000 |
|---|---|---|
| Architektúra | Ampere | Ampere |
| CUDA jadier | 3584 | 6144 |
| VRAM | 12 GB GDDR6 | 16 GB GDDR6 |
| Pamäťová zbernica | 192-bit | 256-bit |
| Šírka pásma pamäte | ~360 GB/s | ~448 GB/s |
| TDP | 170 W | 140 W |
| Formát | Dual-slot (consumer GPU) | Single-slot (workstation GPU) |
| Výstupy | HDMI + 3× DisplayPort | 4× DisplayPort |
| ECC podpora | Nie | Áno |
| NVENC / NVDEC | Áno | Áno |
| Cena (orientačná) | ~300–400 € | ~900–1200 € |
| Zameranie | Gaming / Hobby AI | Workstation / AI / Dátové centrá |
Zhrnutie
- RTX A4000 má viac CUDA jadier, väčšiu VRAM a vyššiu pamäťovú priepustnosť.
- Je optimalizovaná pre profesionálne použitie (AI, CAD, DCC, RAG).
- RTX 3060 je vhodná na základné AI experimenty, ale je limitovaná menšou VRAM.
Prehľad dostupných LLM modelov na serveri (OLLAMA)
Modely pre Cybersecurity QA & Analýzu
| Model | Veľkosť | Odporúčanie |
|---|---|---|
nous-hermes2:latest |
6.1 GB | QA, bezpečnostné poradenstvo |
nous-hermes:13b-q4_0 |
7.4 GB | Pokročilé odpovede, robustné QA |
nous-hermes:13b |
7.4 GB | Alternatívna varianta |
openhermes:latest |
4.1 GB | Ľahšia alternatíva pre QA |
Modely pre prácu s kódom / audit
| Model | Veľkosť | Odporúčanie |
|---|---|---|
codellama:13b-instruct |
7.4 GB | Silný model na kód, skripty, audity |
codellama:7b-instruct |
3.8 GB | Ľahšia varianta, pre viac služieb |
Všeobecné technické modely (fallback)
| Model | Veľkosť | Poznámka |
|---|---|---|
llama3:8b |
4.7 GB | Stabilný, rýchly, kvalitné odpovede |
llama3.1:latest |
4.9 GB | Novšia varianta s vylepšeniami |
mistral:7b |
4.1 GB | Rýchly, výborný v odpovediach |
gemma:2b |
1.7 GB | Úsporný model, vhodný na testy |
phi:latest |
1.6 GB | Malý, vhodný na poznámky |
Embedding model pre RAG
| Model | Veľkosť |
|---|---|
nomic-embed-text:latest |
274 MB |
Poznámka: Všetky modely bežia pohodlne na RTX A4000 (64 GB RAM). Otestované s OpenWebUI.